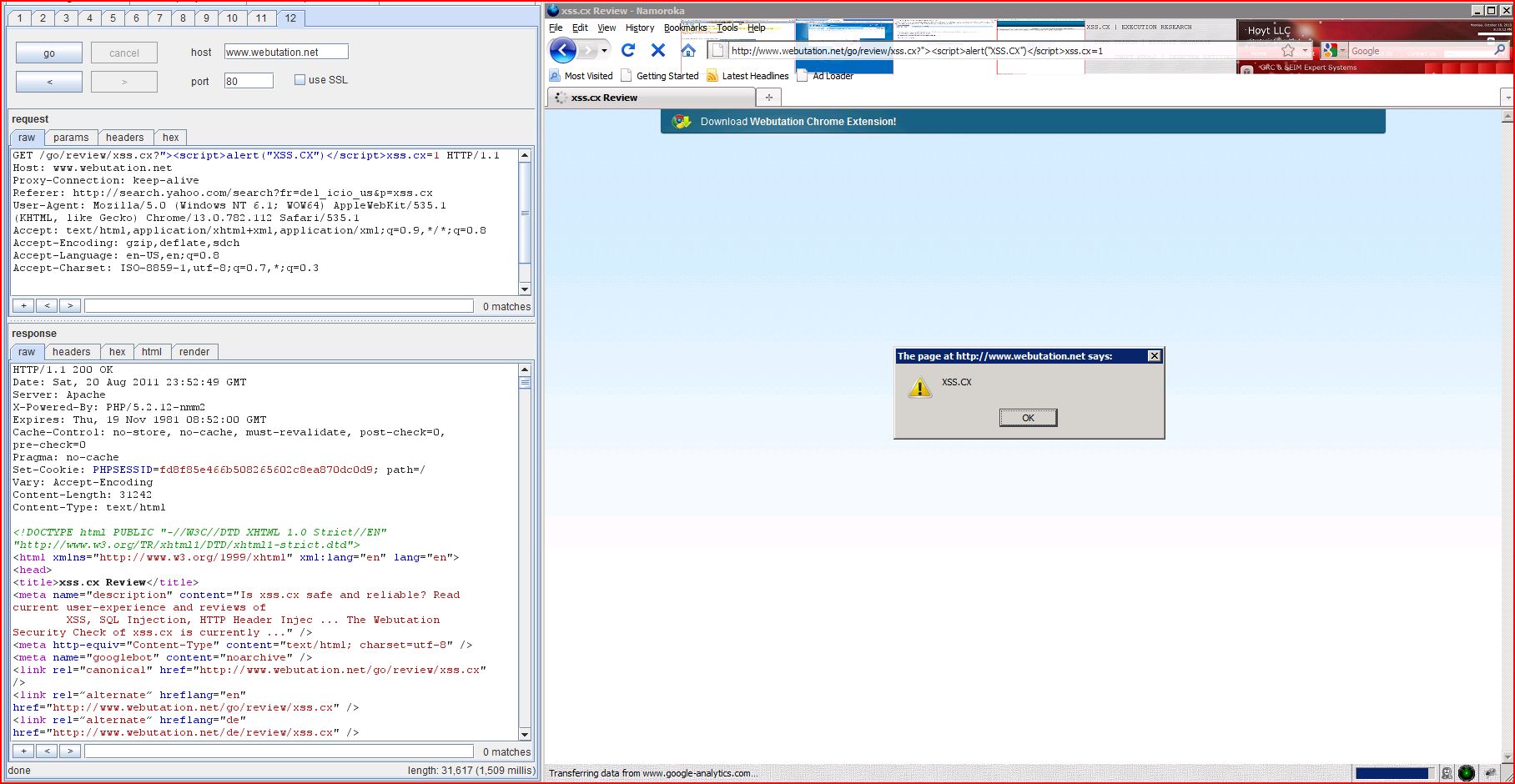
The name of an arbitrarily supplied request parameter is copied into the value of an HTML tag attribute which is encapsulated in double quotation marks. The payload 2563d"><script>alert(1)</script>13d2b541fb7 was submitted in the name of an arbitrarily supplied request parameter. This input was echoed unmodified in the application's response.
This proof-of-concept attack demonstrates that it is possible to inject arbitrary JavaScript into the application's response.
Issue background
Reflected cross-site scripting vulnerabilities arise when data is copied from a request and echoed into the application's immediate response in an unsafe way. An attacker can use the vulnerability to construct a request which, if issued by another application user, will cause JavaScript code supplied by the attacker to execute within the user's browser in the context of that user's session with the application.
The attacker-supplied code can perform a wide variety of actions, such as stealing the victim's session token or login credentials, performing arbitrary actions on the victim's behalf, and logging their keystrokes.
Users can be induced to issue the attacker's crafted request in various ways. For example, the attacker can send a victim a link containing a malicious URL in an email or instant message. They can submit the link to popular web sites that allow content authoring, for example in blog comments. And they can create an innocuous looking web site which causes anyone viewing it to make arbitrary cross-domain requests to the vulnerable application (using either the GET or the POST method).
The security impact of cross-site scripting vulnerabilities is dependent upon the nature of the vulnerable application, the kinds of data and functionality which it contains, and the other applications which belong to the same domain and organisation. If the application is used only to display non-sensitive public content, with no authentication or access control functionality, then a cross-site scripting flaw may be considered low risk. However, if the same application resides on a domain which can access cookies for other more security-critical applications, then the vulnerability could be used to attack those other applications, and so may be considered high risk. Similarly, if the organisation which owns the application is a likely target for phishing attacks, then the vulnerability could be leveraged to lend credibility to such attacks, by injecting Trojan functionality into the vulnerable application, and exploiting users' trust in the organisation in order to capture credentials for other applications which it owns. In many kinds of application, such as those providing online banking functionality, cross-site scripting should always be considered high risk.
Issue remediation
In most situations where user-controllable data is copied into application responses, cross-site scripting attacks can be prevented using two layers of defences:
Input should be validated as strictly as possible on arrival, given the kind of content which it is expected to contain. For example, personal names should consist of alphabetical and a small range of typographical characters, and be relatively short; a year of birth should consist of exactly four numerals; email addresses should match a well-defined regular expression. Input which fails the validation should be rejected, not sanitised.
User input should be HTML-encoded at any point where it is copied into application responses. All HTML metacharacters, including < > " ' and =, should be replaced with the corresponding HTML entities (< > etc).
In cases where the application's functionality allows users to author content using a restricted subset of HTML tags and attributes (for example, blog comments which allow limited formatting and linking), it is necessary to parse the supplied HTML to validate that it does not use any dangerous syntax; this is a non-trivial task.
Request
GET /go/review/xss.cx?2563d"><script>alert(1)</script>13d2b541fb7=1 HTTP/1.1 Host: www.webutation.net Proxy-Connection: keep-alive Referer: http://search.yahoo.com/search?fr=del_icio_us&p=xss.cx User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.112 Safari/535.1 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Encoding: gzip,deflate,sdch Accept-Language: en-US,en;q=0.8 Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
When an application includes a script from an external domain, this script is executed by the browser within the security context of the invoking application. The script can therefore do anything that the application's own scripts can do, such as accessing application data and performing actions within the context of the current user.
If you include a script from an external domain, then you are trusting that domain with the data and functionality of your application, and you are trusting the domain's own security to prevent an attacker from modifying the script to perform malicious actions within your application.
Issue remediation
Scripts should not be included from untrusted domains. If you have a requirement which a third-party script appears to fulfil, then you should ideally copy the contents of that script onto your own domain and include it from there. If that is not possible (e.g. for licensing reasons) then you should consider reimplementing the script's functionality within your own code.
Request
GET /go/review/xss.cx HTTP/1.1 Host: www.webutation.net Proxy-Connection: keep-alive Referer: http://search.yahoo.com/search?fr=del_icio_us&p=xss.cx User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.112 Safari/535.1 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Encoding: gzip,deflate,sdch Accept-Language: en-US,en;q=0.8 Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
The file robots.txt is used to give instructions to web robots, such as search engine crawlers, about locations within the web site which robots are allowed, or not allowed, to crawl and index.
The presence of the robots.txt does not in itself present any kind of security vulnerability. However, it is often used to identify restricted or private areas of a site's contents. The information in the file may therefore help an attacker to map out the site's contents, especially if some of the locations identified are not linked from elsewhere in the site. If the application relies on robots.txt to protect access to these areas, and does not enforce proper access control over them, then this presents a serious vulnerability.
Issue remediation
The robots.txt file is not itself a security threat, and its correct use can represent good practice for non-security reasons. You should not assume that all web robots will honour the file's instructions. Rather, assume that attackers will pay close attention to any locations identified in the file. Do not rely on robots.txt to provide any kind of protection over unauthorised access.
Request
GET /robots.txt HTTP/1.0 Host: www.webutation.net
Response
HTTP/1.1 200 OK Date: Sat, 20 Aug 2011 23:19:03 GMT Server: Apache Last-Modified: Fri, 04 Mar 2011 16:19:41 GMT ETag: "13c00db-1f6-49daa836a0605" Accept-Ranges: bytes Content-Length: 502 Vary: Accept-Encoding Connection: close Content-Type: text/plain
If a web response states that it contains HTML content but does not specify a character set, then the browser may analyse the HTML and attempt to determine which character set it appears to be using. Even if the majority of the HTML actually employs a standard character set such as UTF-8, the presence of non-standard characters anywhere in the response may cause the browser to interpret the content using a different character set. This can have unexpected results, and can lead to cross-site scripting vulnerabilities in which non-standard encodings like UTF-7 can be used to bypass the application's defensive filters.
In most cases, the absence of a charset directive does not constitute a security flaw, particularly if the response contains static content. You should review the contents of the response and the context in which it appears to determine whether any vulnerability exists.
Issue remediation
For every response containing HTML content, the application should include within the Content-type header a directive specifying a standard recognised character set, for example charset=ISO-8859-1.
If a web response specifies an incorrect content type, then browsers may process the response in unexpected ways. If the specified content type is a renderable text-based format, then the browser will usually attempt to parse and render the response in that format. If the specified type is an image format, then the browser will usually detect the anomaly and will analyse the actual content and attempt to determine its MIME type. Either case can lead to unexpected results, and if the content contains any user-controllable data may lead to cross-site scripting or other client-side vulnerabilities.
In most cases, the presence of an incorrect content type statement does not constitute a security flaw, particularly if the response contains static content. You should review the contents of the response and the context in which it appears to determine whether any vulnerability exists.
Issue remediation
For every response containing a message body, the application should include a single Content-type header which correctly and unambiguously states the MIME type of the content in the response body.