1. Cross-site scripting (reflected)
3. Password field with autocomplete enabled
5. Cross-domain script include
| Severity: | High |
| Confidence: | Certain |
| Host: | https://secure.istoc |
| Path: | /signup |
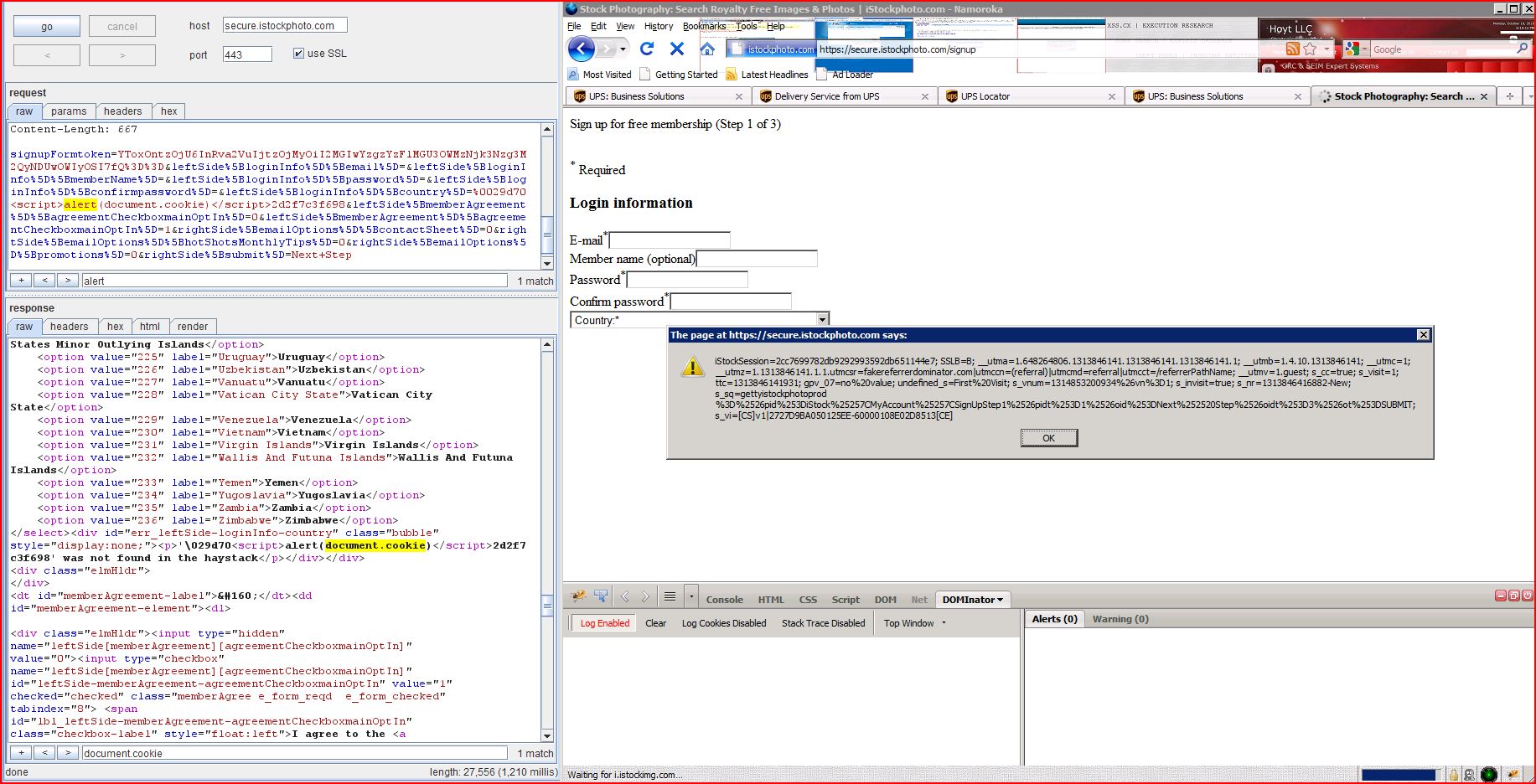
| POST /signup HTTP/1.1 Host: secure.istockphoto.com User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2.13) Gecko/20110504 Namoroka/3.6.13 Accept: text/html,application Accept-Language: en-us,en;q=0.5 Accept-Encoding: gzip,deflate Accept-Charset: ISO-8859-1,utf-8;q=0.7,* Keep-Alive: 115 Connection: keep-alive Referer: http://www.istockphoto Cookie: iStockSession=2cc769 Content-Type: application/x-www-form Content-Length: 611 signupFormtoken ...[SNIP]... |
| HTTP/1.1 200 OK Server: Apache X-Cnection: close Content-Type: text/html; charset=utf-8 Vary: Accept-Encoding Content-Length: 27204 Date: Sat, 20 Aug 2011 13:18:51 GMT Connection: keep-alive Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0 Expires: Thu, 19 Nov 1981 08:52:00 GMT Pragma: no-cache <!DOCTYPE html><html><head><meta charset="utf-8"> <meta name="keywords" content="stock photography, stock agency, photos, digital stock, royalty free" > <meta name="description" content="Browse the be ...[SNIP]... <p>'\029d70<script>alert(1)< ...[SNIP]... |
| Severity: | Low |
| Confidence: | Certain |
| Host: | https://secure.istoc |
| Path: | /crossdomain.xml |
| GET /crossdomain.xml HTTP/1.0 Host: secure.istockphoto.com |
| HTTP/1.0 200 OK Content-Type: text/x-cross-domain Server: BigIP Content-Length: 286 Date: Sat, 20 Aug 2011 13:16:20 GMT Connection: close <?xml version="1.0"?> <!DOCTYPE cross-domain-policy SYSTEM "http://www.macromedia ...[SNIP]... <allow-access-from domain="*.istockphoto.com" /> ...[SNIP]... |
| Severity: | Low |
| Confidence: | Certain |
| Host: | https://secure.istoc |
| Path: | /signup |
| POST /signup HTTP/1.1 Host: secure.istockphoto.com User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2.13) Gecko/20110504 Namoroka/3.6.13 Accept: text/html,application Accept-Language: en-us,en;q=0.5 Accept-Encoding: gzip,deflate Accept-Charset: ISO-8859-1,utf-8;q=0.7,* Keep-Alive: 115 Connection: keep-alive Referer: http://www.istockphoto Cookie: iStockSession=2cc769 Content-Type: application/x-www-form Content-Length: 611 signupFormtoken ...[SNIP]... |
| HTTP/1.1 200 OK Server: Apache X-Cnection: close Content-Type: text/html; charset=utf-8 Vary: Accept-Encoding Content-Length: 27057 Date: Sat, 20 Aug 2011 13:16:19 GMT Connection: keep-alive Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0 Expires: Thu, 19 Nov 1981 08:52:00 GMT Pragma: no-cache <!DOCTYPE html><html><head><meta charset="utf-8"> <meta name="keywords" content="stock photography, stock agency, photos, digital stock, royalty free" > <meta name="description" content="Browse the be ...[SNIP]... <div id="ajaxWinBody"><form id="signupForm" enctype="application/x ...[SNIP]... </label><input type="password" name="leftSide[loginInfo] ...[SNIP]... </label><input type="password" name="leftSide[loginInfo] ...[SNIP]... |
| Severity: | Information |
| Confidence: | Firm |
| Host: | https://secure.istoc |
| Path: | /signup |
| POST /signup HTTP/1.1 Host: secure.istockphoto.com User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2.13) Gecko/20110504 Namoroka/3.6.13 Accept: text/html,application Accept-Language: en-us,en;q=0.5 Accept-Encoding: gzip,deflate Accept-Charset: ISO-8859-1,utf-8;q=0.7,* Keep-Alive: 115 Connection: keep-alive Referer: http://www.istockphoto Cookie: iStockSession=2cc769 Content-Type: application/x-www-form Content-Length: 611 signupFormtoken ...[SNIP]... |
| HTTP/1.1 200 OK Server: Apache X-Cnection: close Content-Type: text/html; charset=utf-8 Vary: Accept-Encoding Content-Length: 27057 Date: Sat, 20 Aug 2011 13:16:19 GMT Connection: keep-alive Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0 Expires: Thu, 19 Nov 1981 08:52:00 GMT Pragma: no-cache <!DOCTYPE html><html><head><meta charset="utf-8"> <meta name="keywords" content="stock photography, stock agency, photos, digital stock, royalty free" > <meta name="description" content="Browse the be ...[SNIP]... <!-- if(typeof istock === "undefined") {istock={};} istock.siteLang="EN" istock.url="http://www istock.cookielessUrl= var SECURITY_TOKEN = "aaa6e92ee15dfe4aa8e5 document.observe("dom var optedInByDefault = ["38","138","223","224"]; var requiresDoubleOptIn = ["81"]; smartform.initialise( </script><script type="text/javascript"> //<!-- Event.observe(window, "load", function(e) { s.formList="signupForm"; s.trackFormList=false; s.trackPageName=true; s.useCommerce=false; s.varUsed="prop30"; s.eventList="Abandon"; s.channel="istock s.prop1="istock s.prop2="istock s.eVar1="istock s.eVar2="istock s.hier1="istock s.events="event22"; s.pageName="iStock s.prop3="en_US"; s.eVar3="en_US"; s.prop40="unregistered"; s.eVar40="unregistered"; s.prop41="Visitor"; s.eVar41="Visitor"; s.server=window.location s.eVar6=window.location s.eVar38="20110820"; s.t(); }); //--> </script> <script type="text/javascript"> //<!-- var lpLanguage = 'english'; var lpUnit = 'istock'; var lpLoginFlag = '0'; var _gaq = _gaq || []; document.observe('dom _gaq.push(['_setAccount', 'UA-86235-1']); _gaq.push(['_setDoma _gaq.push(['_setAllo _gaq.push(['_setAllowHash _gaq.push(['_setVar', 'guest']); _gaq.push(['_trackPa (function() { var ga = document.createElement( ga.src = ('https:' == document.location var g = document.getElements ...[SNIP]... |
| POST /signup HTTP/1.1 Host: secure.istockphoto.com User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2.13) Gecko/20110504 Namoroka/3.6.13 Accept: text/html,application Accept-Language: en-us,en;q=0.5 Accept-Encoding: gzip,deflate Accept-Charset: ISO-8859-1,utf-8;q=0.7,* Keep-Alive: 115 Connection: keep-alive Cookie: iStockSession=2cc769 Content-Type: application/x-www-form Content-Length: 611 signupFormtoken ...[SNIP]... |
| HTTP/1.1 200 OK Server: Apache X-Cnection: close Content-Type: text/html; charset=utf-8 Vary: Accept-Encoding Content-Length: 27324 Date: Sat, 20 Aug 2011 13:17:37 GMT Connection: keep-alive Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0 Expires: Thu, 19 Nov 1981 08:52:00 GMT Pragma: no-cache <!DOCTYPE html><html><head><meta charset="utf-8"> <meta name="keywords" content="stock photography, stock agency, photos, digital stock, royalty free" > <meta name="description" content="Browse the be ...[SNIP]... <!-- if(typeof istock === "undefined") {istock={};} istock.siteLang="EN" istock.url="http://www istock.cookielessUrl= var SECURITY_TOKEN = "c97d122ed44c321d4e84 document.observe("dom var optedInByDefault = ["38","138","223","224"]; var requiresDoubleOptIn = ["81"]; smartform.initialise( </script><script type="text/javascript"> //<!-- Event.observe(window, "load", function(e) { try { var trackImg = new Image(); trackImg.src = ('https:' == document.location } catch (err) { // } s.formList="signupForm"; s.trackFormList=false; s.trackPageName=true; s.useCommerce=false; s.varUsed="prop30"; s.eventList="Abandon"; s.channel="istock s.prop1="istock s.prop2="istock s.eVar1="istock s.eVar2="istock s.hier1="istock s.events="event22"; s.pageName="iStock s.prop3="en_US"; s.eVar3="en_US"; s.prop40="unregistered"; s.eVar40="unregistered"; s.prop41="Visitor"; s.eVar41="Visitor"; s.server=window.location s.eVar6=window.location s.eVar38="20110820"; s.t(); }); //--> </script> <script type="text/javascript"> //<!-- var lpLanguage = 'english'; var lpUnit = 'istock'; var lpLoginFlag = '0'; var _gaq = _gaq || []; document.observe('dom _gaq.push(['_setAccount', 'UA-86235-1']); _gaq.push(['_setDoma _gaq.push(['_setAllo _gaq.push(['_setAllowHash _gaq.push(['_setVar', 'guest']); _gaq.push(['_trackPa (function() { var ga = document.cre ...[SNIP]... |
| Severity: | Information |
| Confidence: | Certain |
| Host: | https://secure.istoc |
| Path: | /signup |
| POST /signup HTTP/1.1 Host: secure.istockphoto.com User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2.13) Gecko/20110504 Namoroka/3.6.13 Accept: text/html,application Accept-Language: en-us,en;q=0.5 Accept-Encoding: gzip,deflate Accept-Charset: ISO-8859-1,utf-8;q=0.7,* Keep-Alive: 115 Connection: keep-alive Referer: http://www.istockphoto Cookie: iStockSession=2cc769 Content-Type: application/x-www-form Content-Length: 611 signupFormtoken ...[SNIP]... |
| HTTP/1.1 200 OK Server: Apache X-Cnection: close Content-Type: text/html; charset=utf-8 Vary: Accept-Encoding Content-Length: 27057 Date: Sat, 20 Aug 2011 13:16:19 GMT Connection: keep-alive Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0 Expires: Thu, 19 Nov 1981 08:52:00 GMT Pragma: no-cache <!DOCTYPE html><html><head><meta charset="utf-8"> <meta name="keywords" content="stock photography, stock agency, photos, digital stock, royalty free" > <meta name="description" content="Browse the be ...[SNIP]... </script><script type="text/javascript" src="https://i.istockimg <script type="text/javascript" src="https://i.istockimg ...[SNIP]... <![endif]--> <script type="text/javascript" src="https://i.istockimg <script type="text/javascript" src="https://i.istockimg ...[SNIP]... <![endif]--> <script type="text/javascript" src="https://i.istockimg ...[SNIP]... |
| Severity: | Information |
| Confidence: | Certain |
| Host: | https://secure.istoc |
| Path: | /signup |
| GET /robots.txt HTTP/1.0 Host: secure.istockphoto.com |
| HTTP/1.0 200 OK Server: Apache Content-Length: 26 X-Cnection: close Content-Type: text/plain Date: Sat, 20 Aug 2011 13:16:21 GMT Connection: close Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0 Expires: Thu, 19 Nov 1981 08:52:00 GMT Pragma: no-cache User-agent: * Disallow: / |
| Severity: | Information |
| Confidence: | Certain |
| Host: | https://secure.istoc |
| Path: | / |
| Issued to: | secure.istockphoto.com,ST=Alberta |
| Issued by: | Akamai Subordinate CA 3 |
| Valid from: | Fri Jul 29 15:31:19 GMT-06:00 2011 |
| Valid to: | Sun Jul 29 15:31:19 GMT-06:00 2012 |
| Issued to: | Akamai Subordinate CA 3 |
| Issued by: | GTE CyberTrust Global Root |
| Valid from: | Thu May 11 09:32:00 GMT-06:00 2006 |
| Valid to: | Sat May 11 17:59:00 GMT-06:00 2013 |
| Issued to: | GTE CyberTrust Global Root |
| Issued by: | GTE CyberTrust Global Root |
| Valid from: | Wed Aug 12 18:29:00 GMT-06:00 1998 |
| Valid to: | Mon Aug 13 17:59:00 GMT-06:00 2018 |